Overview
Clustering is one of the highest-leverage things you can do for query performance on a lake table — it makes file pruning sharp and collapses the small-file problem in a single pass. The catch is that the sort-and-rewrite isn’t free, which is why a lot of teams know they should cluster and don’t.
This post walks through what clustering fixes, why the cost holds teams back, and the native execution path Quanton just shipped to make it ~4× faster on both Apache Hudi and Apache Iceberg.
The problem
Two file-layout problems show up on almost every table at scale:
- Queries scan too many files. Even a well-partitioned table ends up with hundreds of files per partition with overlapping min/max ranges. A predicate filter that should hit a handful of files ends up touching most of them, because the engine can’t rule them out.
- Small files pile up. Streaming ingest, frequent commits, and many concurrent writers push the table toward thousands of tiny files — driving up planning time, metadata overhead, and query latency.
Clustering sorts rows on the columns you actually filter on and rewrites them into fewer, larger, range-tight files. File pruning gets sharp, and the small-file count collapses — in the same pass.
The catch
Clustering isn’t free. The sort and rewrite add up on large tables — and that cost is exactly why a lot of teams know they should cluster and still don’t. The maintenance window is too expensive, so the layout problem compounds instead.
Is clustering the same as compaction?
Compaction and clustering attack the same small-file problem — the difference is that clustering also sorts. Compaction (bin-packing) merges small files into larger ones without reordering rows, so it fixes file count but not pruning. Clustering sorts rows on your filter columns while it merges, so it fixes both in one rewrite.
Every table format exposes both, under different names:
| Format | Compaction (bin-pack) | Clustering (sort + rewrite) |
|---|---|---|
| Delta Lake | OPTIMIZE | OPTIMIZE ... ZORDER BY / liquid clustering |
| Apache Iceberg | rewrite_data_files(strategy => 'binpack') | rewrite_data_files(strategy => 'sort') |
| Apache Hudi | clustering (small-file merge) | run_clustering(order => ...) |
(In Hudi, note that “compaction” also names a separate Merge-on-Read operation — merging log files into base files. The small-file fix is clustering.)
If you’re paying for the rewrite anyway, sorting while you merge usually offers more ROI: same read/write costs, sharper pruning with some additional sorting costs.
Does repartition or coalesce fix small files?
No — repartition() and coalesce() control how many files your next write produces; they do nothing for the small files already in the table. The difference between the two:
repartition(n) | coalesce(n) | |
|---|---|---|
| Shuffle | Full shuffle | None — merges existing partitions |
| Partition sizes | Even | Can be uneven (skew risk) |
| Direction | Increase or decrease count | Decrease only |
| Cost | High (network + sort) | Low |
| Use it for | Rebalancing before an expensive stage or a clean write | Cheaply cutting output file count when balance doesn’t matter |
Writing with repartition(n) (or coalesce(n)) is how you stop adding small files. Cleaning up the ones you already have is table maintenance — the compaction and clustering procedures above.
How Quanton fixes it
The Quanton Operator now has a high-performance native execution path for clustering on both Apache Hudi and Apache Iceberg. Same cluster, same data, same SQL, same procedure. One flag:
sparkConf:
spark.quanton.clustering.accelerate: "true"With it set, the sort inside your existing clustering procedure runs through Quanton’s vectorized engine instead of standard Spark. The procedures don’t change:
-- Iceberg
CALL spark_catalog.system.rewrite_data_files(
table => 'default.events_iceberg',
strategy => 'sort',
sort_order => 'region ASC NULLS LAST, ts ASC NULLS LAST'
)-- Hudi
CALL run_clustering(order => 'region,ts', op => 'scheduleandexecute')Comparison at 2 TB scale
2 TB load test, identical resources across both engines:
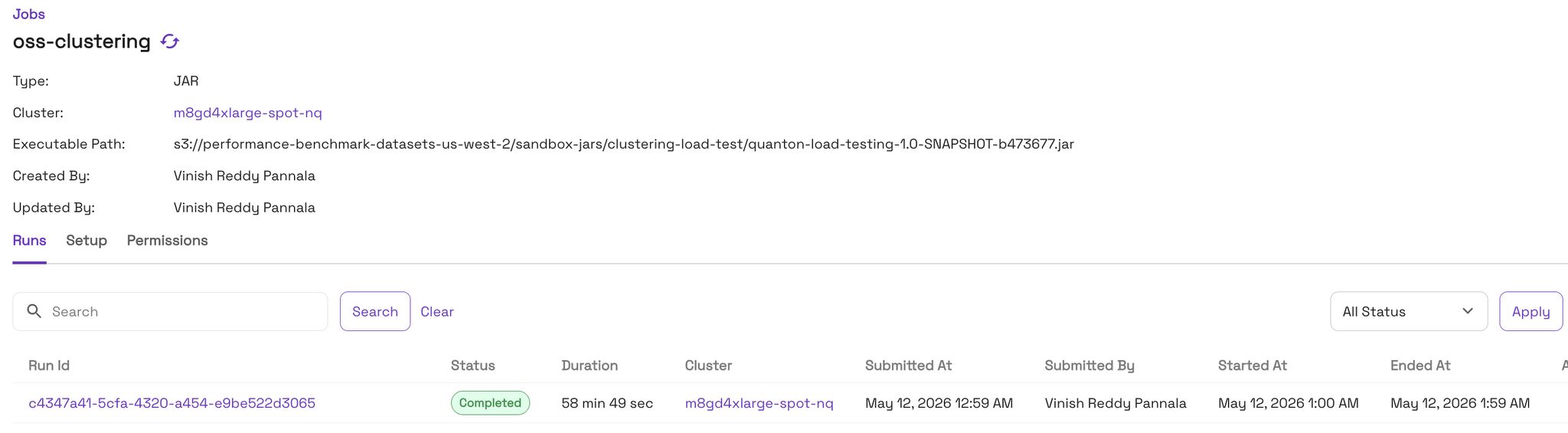
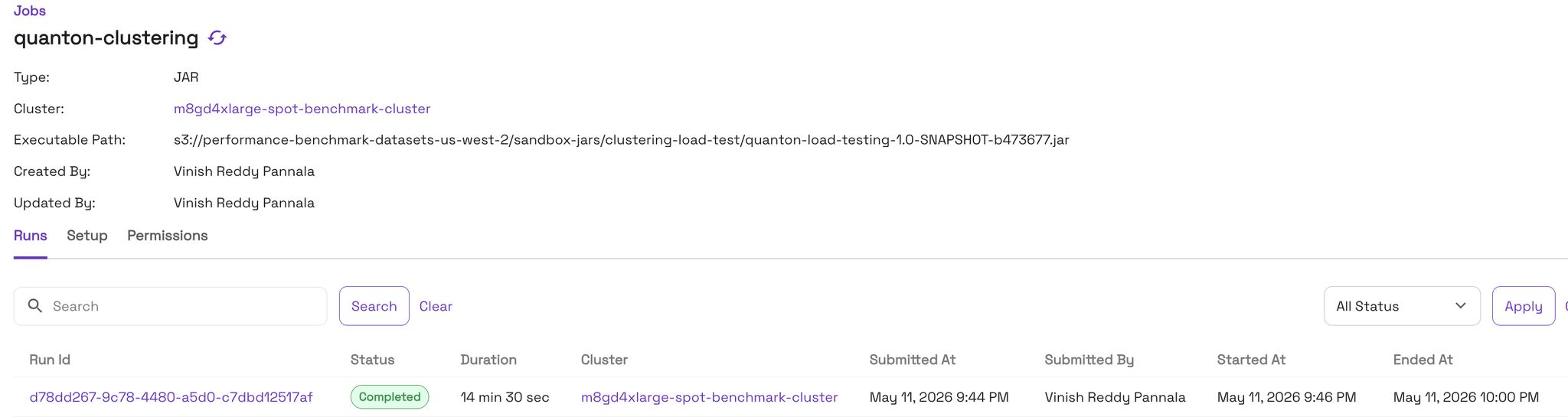
That’s about 75% less wall-time. Spend the time you save how you like: cluster 4× more often for the same cost, or cluster much larger tables inside the maintenance window you already have.
See it on a real table
The clustering-demo in the quanton-operator repo is self-contained — it writes a deliberately fragmented table, clusters it, and verifies the rows are preserved and the files compacted. Runs on a local minikube (4 CPUs / 8 GB RAM) with the Spark and Quanton operators installed.
Iceberg:
kubectl apply -f quanton-iceberg-clustering-demo.yaml
kubectl logs -f quanton-iceberg-clustering-demo-driver -n defaultHudi:
kubectl apply -f quanton-hudi-clustering-demo.yaml
kubectl logs -f quanton-hudi-clustering-demo-driver -n defaultThe Iceberg run ends with 100 rows preserved, files compacted 40 -> 1 — 40 fragmented files collapsed into 1, with every row intact.
Run it with an agent
The repo ships a Claude Code skill — run-clustering — that runs the whole demo for you. Clone the repo, launch Claude, and invoke the skill:
git clone https://github.com/onehouseinc/quanton-operator
cd quanton-operator
claude> /run-clusteringIt lets you pick Hudi, Iceberg, or both, forces a many-tiny-files layout, runs the native clustering procedure with spark.quanton.clustering.accelerate=true, and reports whether acceleration succeeded.
Takeaway
Clustering is one of the best levers you have for query performance — when the maintenance cost doesn’t scare you off it. Quanton’s native execution path makes that cost 4× smaller, so “we should cluster more often” can actually become “we do.”
Try it on your own tables now!
